向量(和词向量)
矢量数据库保存文档、图像和音频文件等信息,这些信息不适合传统数据库所期望的表格格式。相反,这些数据的存储、检索和管理是以向量的形式完成的。在数学术语中,向量是具有大小值和方向值的对象。
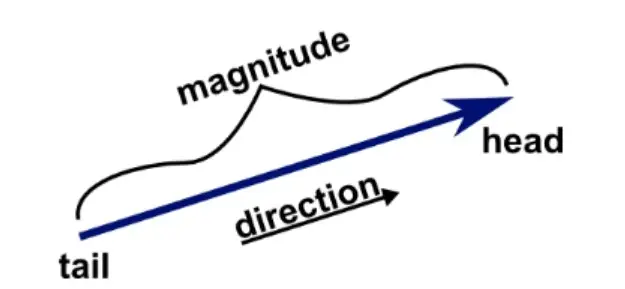
实际上,向量描述了两点之间相对于给定维数的关系。在词向量的上下文中,想想单词“男孩”与 X、Y 平面上的其他名词的关系,其中 X 是性别,Y 是年龄。
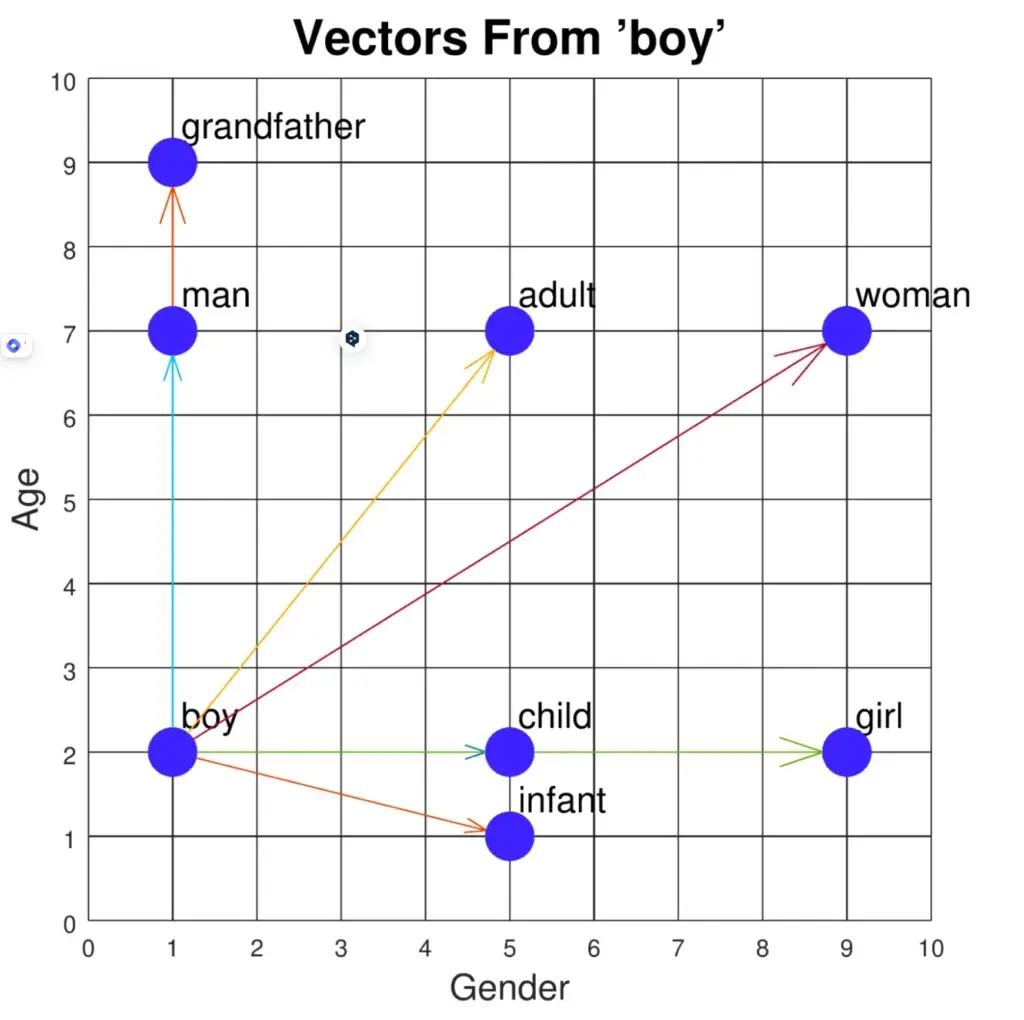
上面的向量量化了“男孩”与其他每个名词的关系。例如,从“男孩”到“女人”,与“男孩”到“孩子”的向量相比,我们看到的幅度要大得多,方向也不同。
这是有道理的,因为“女人”比“男孩”大得多,并且具有异性,而“孩子”可能与“男孩”具有相同的相对年龄,但是一个性别中立的名词。
在这种比较中,我们可以说“孩子”这个词相对于其他名词来说,与我们对“男孩”的查询最相似。这种相似性使我们能够在向量数据库中进行搜索。
搜索
在向量数据库中搜索的核心思想是,相似的项目将具有相似的向量。所谓“相似”,是指向量在向量空间中彼此接近。两个向量之间的距离可以使用各种方法测量,余弦相似度和欧几里得距离是最常见的两种。
让我们从 L2 范数或欧几里得距离开始,因为这是最直接、最容易理解的方法。你可能会从中学代数中认出欧几里得距离。
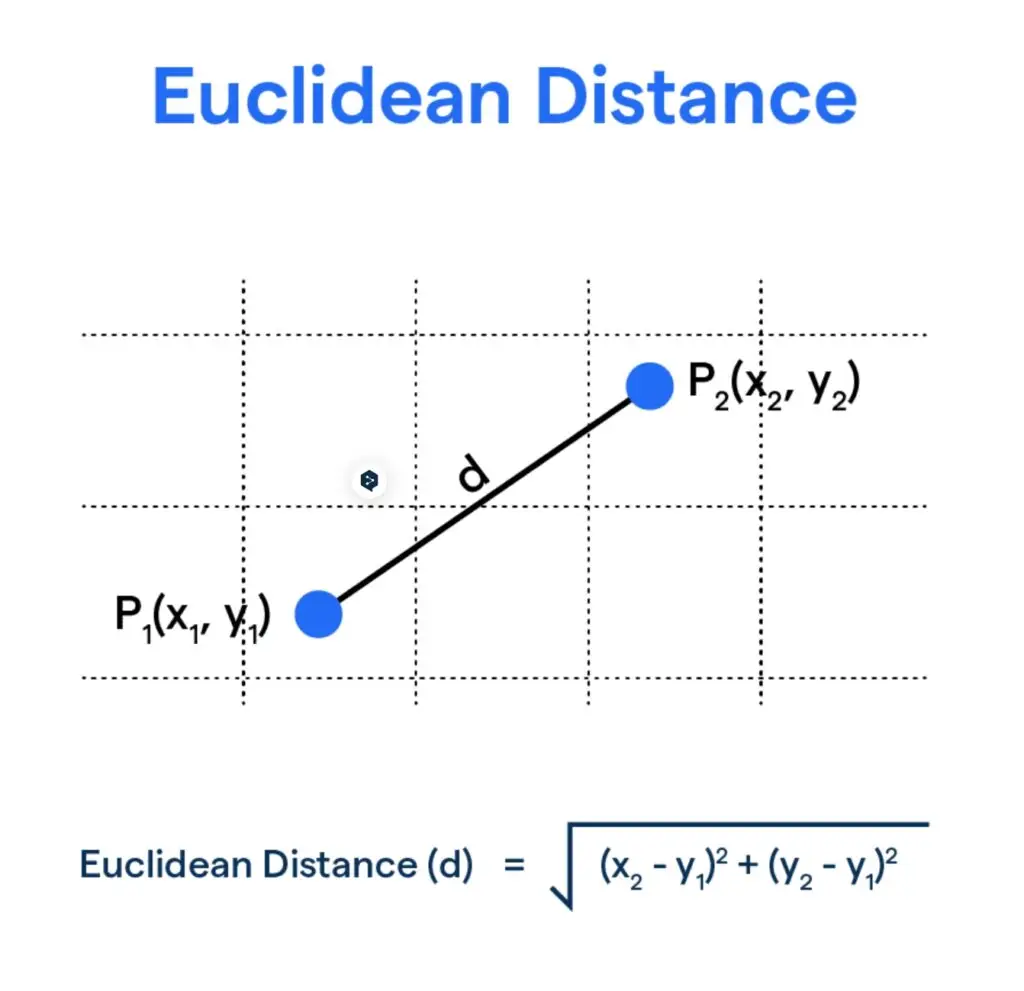
如上图所示,欧几里得距离测量 X、Y 平面上两点之间的“直线”距离。在搜索中使用时,我们计算查询向量与数据库中给定数量的项目向量之间的欧几里得距离。与查询距离最小的向量被视为最相似的项。
相比之下,余弦相似度测量两个向量之间角度的余弦。简单地说,角度越小,查询向量与该特定项目越相似。
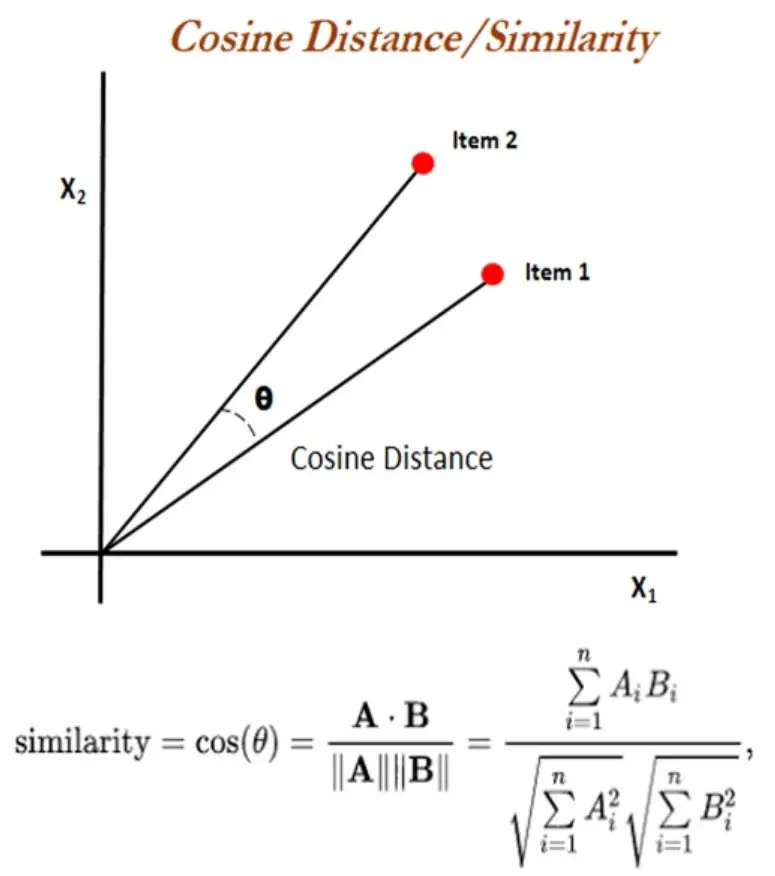
例如,如果查询向量和项目向量相同,则它们之间的角度将为 0°,余弦相似度分数将为 1。但是,如果没有相似性,您将看到接近 180° 的角度和接近 0 的相似性分数。("boy" == "boy")("boy" != "tennis")
大多数向量数据库使用余弦相似度作为其默认检索函数,其中计算查询向量与给定数量的项向量之间的余弦相似度,以确定每个项与查询的相似程度。与查询具有最高余弦相似性分数的项被视为最相似的项。
向量数据库和关系数据库有什么区别?
数据表示和用例
关系数据库以行和列(表格格式)存储数据,每行表示一个实体,每列表示该实体的一个属性。另一方面,向量数据库将数据存储为向量——可以表示项目本质的数字序列。
这就是为什么它使它们适合存储和检索非传统数据源,如文档、图像和音频文件。
查询机制
关系数据库依赖于 SQL(结构化查询语言)进行查询。您可能会要求提供符合特定条件的数据(例如“余额小于 0 的所有帐户”)。在向量数据库中,将搜索向量与数据库中存储的向量进行比较,以仅查找最相似的向量。因此,您可以期望与向量数据库的库进行交互,而不是与 SQL 等整个语言进行交互。
什么是嵌入模型以及如何在矢量数据库中使用它们?
嵌入模型是将您的原始数据(pdf、mp3 等)转换为矢量嵌入的方法。这些嵌入的目标是以这样一种方式表示数据,即向量之间的几何距离是有意义的。换言之,原始数据空间中的相似项在嵌入向量空间中应该靠得很近,而不同的项应该相距很远。
一个常见的例子是自然语言处理中的词嵌入。单词被转换为向量,使得具有相似含义或在相似上下文中使用的单词在向量空间中靠得很近。例如,我们之前的“男孩”和“孩子”向量示例在这个空间中比“男孩”和“女人”的向量更接近。
您的矢量数据库可能有一个默认的嵌入模型,该模型已被抽象掉,因此您无需自己选择模型。但是,生成式 AI 领域正在迅速发展,您可能需要尝试使用不同的模型来尝试提高性能或搜索相关性。
什么是最好的开源向量数据库?
您应该始终根据特定组件的功能如何与项目要求保持一致来选择技术。如果要查找原型设计的起点,可能需要调查以下一些选项:
FAISS(Facebook AI 相似性搜索):FAISS 擅长索引、搜索和聚类大量高维向量,尤其是在图像识别和语义文本搜索方面。它在内存消耗和查询时间方面非常高效,能够处理数百个向量维度。常见的应用包括大规模图像搜索引擎和文本数据中的语义搜索系统。
Milvus:Milvus 擅长向量索引和查询,使用先进的算法在大型数据集中快速检索。它与 PyTorch 和 TensorFlow 等框架很好地集成在一起。应用程序跨越各个行业,包括电子商务推荐系统、图像和视频分析,以及用于文档聚类和语义搜索的自然语言处理。
Chroma:Chroma 从头开始设计,旨在与大型语言模型 (LLM) 应用程序集成,并处理多种数据类型和格式。它对音频数据特别有效,使其适用于基于音频的搜索引擎、音乐推荐和其他以音频为中心的应用程序。
矢量数据库有哪些托管云服务?
Pinecone:Pinecone 以其用户友好的界面和专注于大规模机器学习应用程序而闻名,它支持高维向量数据库,用于相似性搜索、推荐系统和语义搜索等用例,同时抽象出基础设施的责任。它提供实时数据分析功能,在网络安全中可用于威胁检测和各种系统(包括 GPT 模型和 Elasticsearch)的集成。
Snowflake Data Cloud:凭借其新的 Snowflake Cortex 产品,Snowflake 现在为 LLM 应用程序开发提供了一个完全托管的平台。这些服务包括快速数据分析和模型即服务,包括 Meta AI 的 Llama 2 模型。Snowpark Container Services 是另一个关键组件,它允许开发人员使用 Snowflake 托管的基础设施部署、管理和扩展自定义容器化工作负载,包括开源 LLM。
关于向量数据库,Cortex 包括向量嵌入和相似性搜索功能以及 Streamlit 集成,用于以最少的编码开发 LLM 应用程序界面。Snowpark Container Services 为 LLM 应用程序提供了进一步的自定义选项,支持容器化工作负载和自定义用户界面的部署。Snowflake强调其对安全和治理的关注,在其平台的安全边界内提供这些功能。
综上所述
今天,我们了解了矢量数据库如何为存储文档、图像和音频等非表格数据提供独特的解决方案。我们探讨了余弦相似度和欧几里得距离这两个主要的相似性指标,以及向量数据库在数据表示和查询机制方面与关系数据库的区别。
我们还了解到嵌入模型在将原始数据转换为有意义的向量嵌入方面的重要性。我们回顾了 FAISS、Milvus 和 Chroma 等开源矢量数据库,以及 Pinecone 和 Snowflake Cortex 等托管云服务。
您应该对自己对这项技术的了解及其所能实现的目标充满信心,但您不必独自旅行。phData的工程团队随时为您提供帮助!





