将数据科学部署为完全透明、灵活的数据应用,供技术和业务最终用户使用。
如果数据是新的石油,那么我们就缺少了管道。
在投资数据素养时,公司在两个主要领域投入了大量精力:
- 建立数据科学团队,用数据回答问题,以及
- 提高业务线团队的技能,了解要问什么问题
一旦将大量资源投入到这两个领域,许多领导者会惊讶地发现一切都进展得如此缓慢。模型很少投入生产,两个团队之间的反馈周期非常长。
作为一门学科,数据科学仍然面临着最后一英里的问题。
将数据科学转换为数据应用和服务并非易事,通常需要依赖 IT 或有关部署客户端服务器体系结构的深厚技术知识。数据专家面临着艰苦的战斗,不仅要创建数据科学,还要向技术和业务同行解释数据科学,以便即使是最小的项目也能实现。
在KNIME,我们的目标是直面这个问题,并在数据科学生命周期的每一步为数据团队提供支持。朝着这个方向迈出的重要一步是 KNIME 数据应用程序。我们使数据团队能够构建完全透明、灵活的数据应用程序,而无需任何 HTML、CSS、Javascript、API 整理或暂存环境。
提示: 为您的数据科学构建用户体验,无需前端语言
使用 KNIME 的数据应用程序
KNIME 分析平台的核心是可视化编程环境。此环境用于引入、清理、混合、探索,然后最终生产数据科学。同一环境可用于构建和自动部署数据应用。
KNIME 用户可以灵活地构建各种数据应用程序,并精确控制:
- 交互性:最终用户可以浏览和控制屏幕上显示的数据的程度
- 复杂性:基础数据科学的复杂程度
特别是数据科学的复杂性,是KNIME数据应用程序与Tableau或Qlik等BI解决方案的区别所在(尽管它们可以串联使用)。虽然许多 BI 工具使交互式可视化变得更加容易,但 KNIME 允许对数据的转换方式以及幕后发生的数据科学进行精细控制。
这种级别的自定义可确保数据团队中的任何人都可以为技术和业务线最终用户构建数据应用。对于业务线最终用户,该应用程序可以设计为通过直观的界面引导他们理解、探索或操作他们的数据。这种方法称为引导式分析。
您可以构建数据应用,以便:
- 为您的领导团队提供业务 KPI 和自动生成的预测仪表板,
- 指导领域专家访问、可视化和探索他们的数据,
- 使您的数据科学团队能够通过高度交互的界面探索复杂的机器学习算法。
所有这些都可以使用相同的拖放式直观界面来完成。
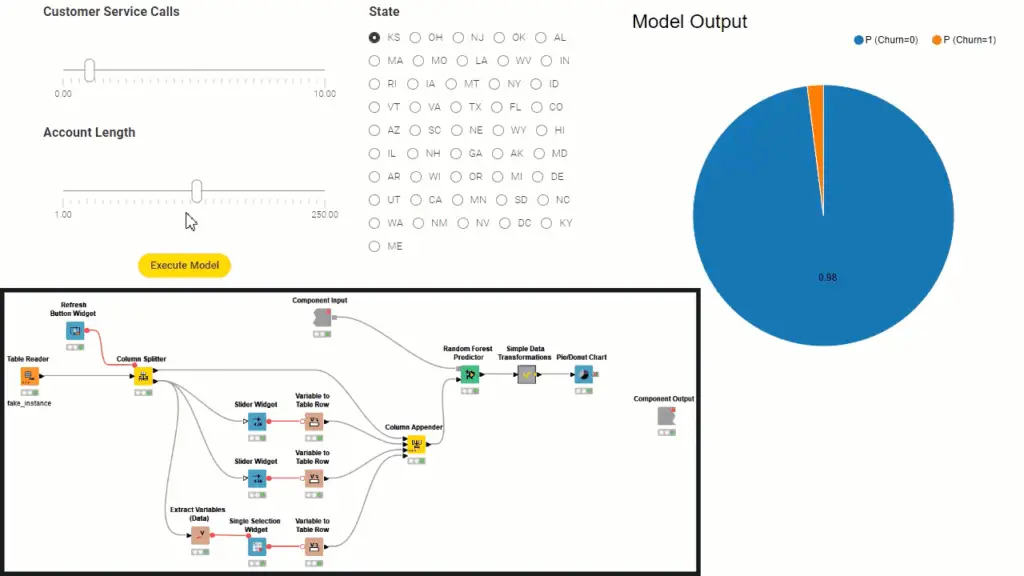
图 1.由 KNIME 工作流生成的数据应用程序示例(图像的下半部分),显示了探索复杂机器学习算法的交互式界面
通过包含适当的组件,可以在 KNIME 中构建的任何工作流部署为数据应用程序,从而为用户提供对底层数据科学和 UX 的重要选择和控制。
如何构建数据应用
通过拖放节点,KNIME 工作流几乎可以用于创建和生产数据科学的每个步骤。数据应用程序是使用 KNIME 分析平台中的特殊节点构建的,允许用户调整每个页面的外观和感觉,构建交互,并将应用程序中的多个页面串在一起。
将此放在上下文中,一个典型的 KNIME 数据科学项目,端到端,如下所示:
- 首先,您可以在 KNIME 的可视化编程环境中访问和混合您的数据。
- 然后,您可以使用众多内置算法之一,或访问集成在 KNIME 开放生态系统中的任意数量的技术(Python 等脚本语言、H2O 等机器学习库等)。
- 从那里,通过将特殊节点拖放到 KNIME 工作台上,使用相同的可视化、直观环境构建您的数据应用程序。
- 部署到KNIME服务器,并通过安全的WebPortal或通过可共享的嵌入式链接共享您的数据应用程序。
- 与 5、10 或 1000 个最终用户共享。
- 最后,根据反馈进行监控和轻松调整。
此 KNIME 功能将创建数据应用程序的时间从几个月缩短到几天。结果为组织带来了更快的见解,并消除了数据专家的挫败感和障碍。最重要的是,它最终降低了业务团队和数据科学团队之间的壁垒。
迈向数据科学专业化的第一步
数据科学家拥有创建数据科学所需的所有工具:摄取和清理数据、混合、探索和分析,在某些情况下,还可以根据数据进行预测。在某种程度上,这些能力已经存在了几十年。
困难的部分是扩展。
为了有效地支持“数据驱动”的业务,数据科学家必须超越一次性的预测或分析。他们需要一种方法来打包他们的发现并与人类和机器分享。为此,KNIME平台在创建和生产过程的每一步都为数据专家提供支持。





